
Google will not render Javascript on noindex pages. This test will see if a page with only 1 link from a page that is marked as noindex (x-robots and on-page) will get found.
Update: Yes, Google will use noindex pages for link discovery
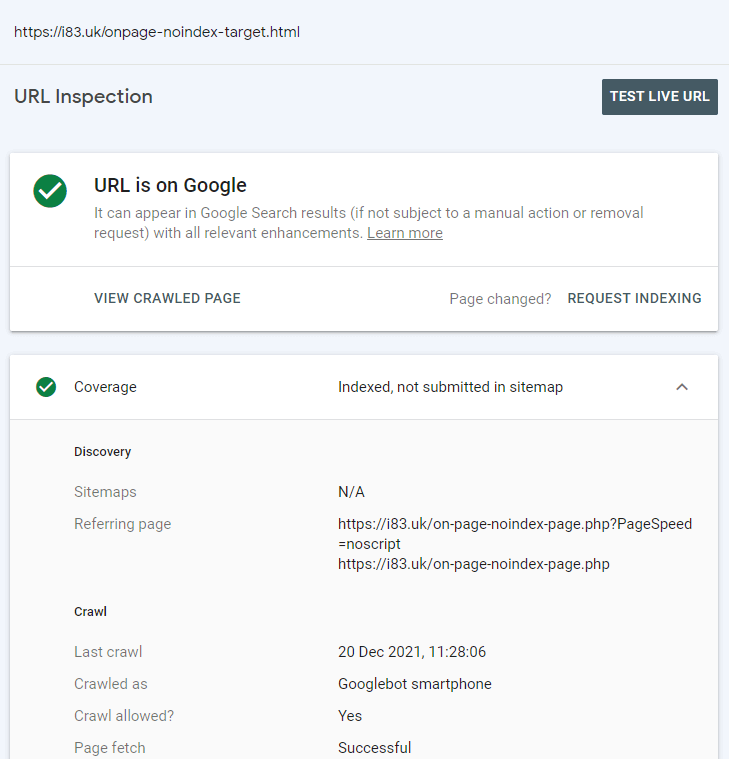
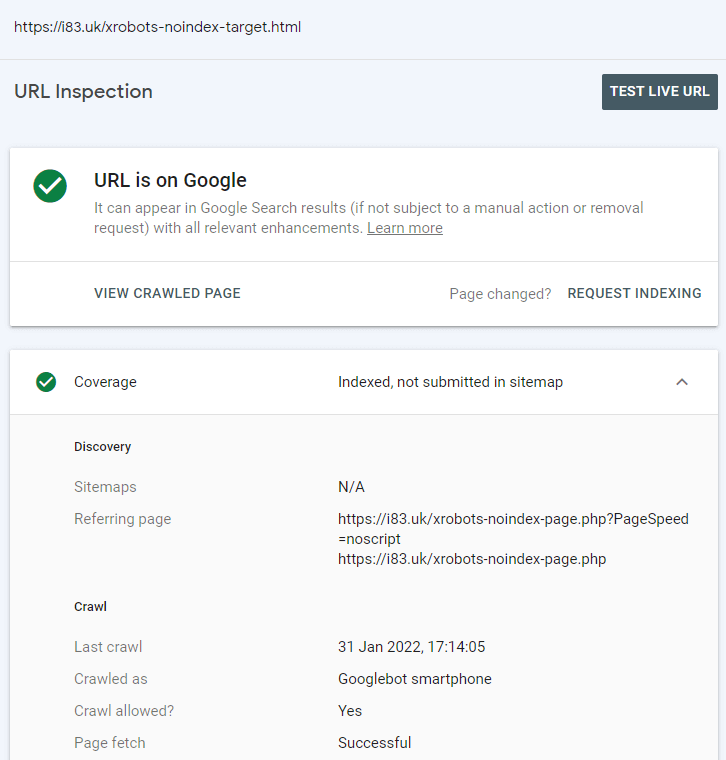
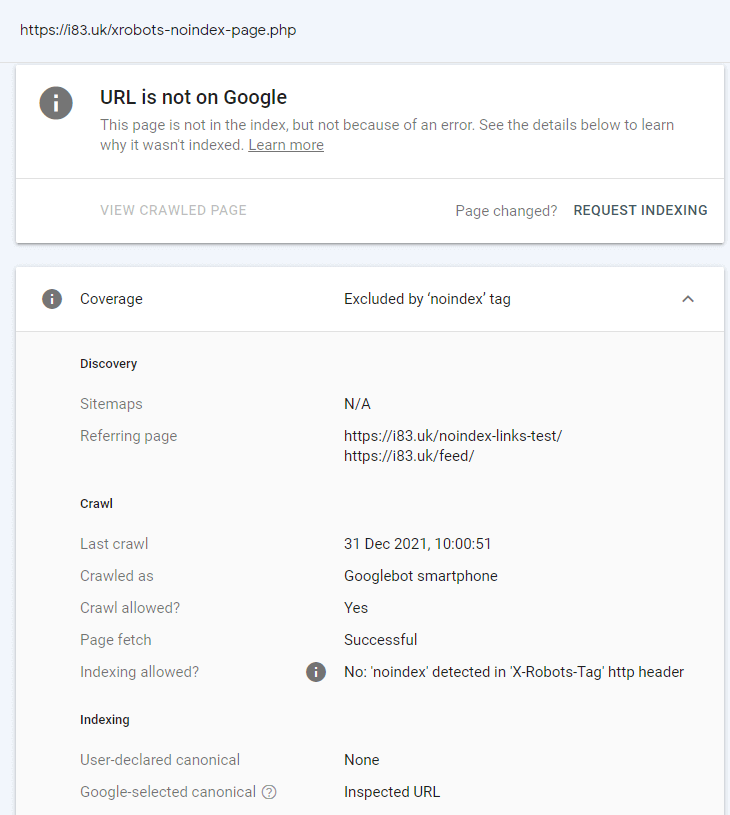
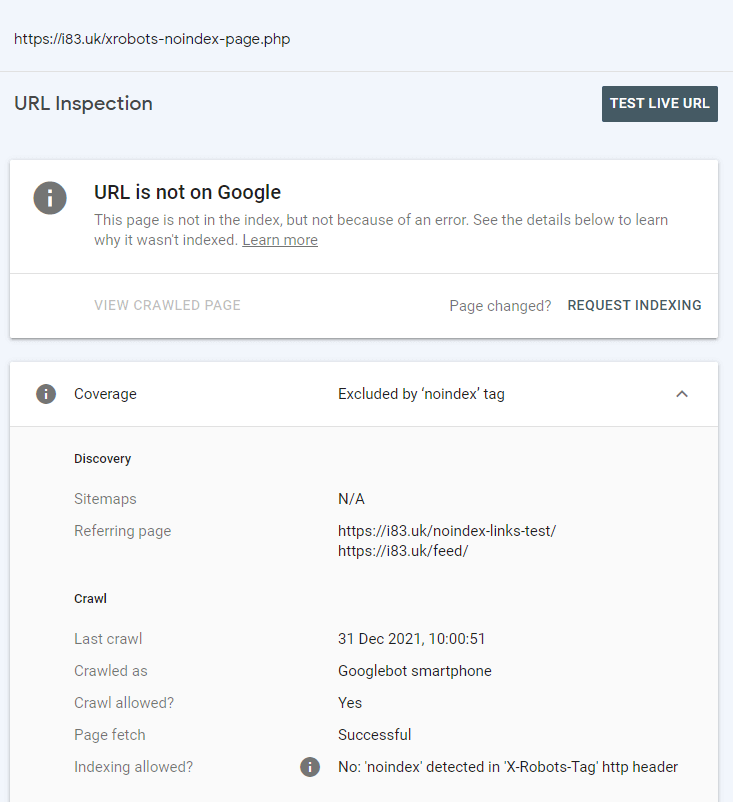
Both candidate pages that were linked to from a pages that were noindex via x-robots and on-page were indexed. Google Search Console confirmed these URLs were discovered from these noindexed pages.
The original test and explanation:
I saw on Google’s docs on Javascript and SEO that they said, “If Googlebot encounters noindex, it skips rendering and JavaScript execution”. Although I hadn’t seen this explicitly written before, it makes perfect sense to me. Executing Javascript is resource-intensive and there is already a queue that can seemingly take weeks to get Javascript-rendered pages in the index. There doesn’t seem to be a logical reason why Google would prioritise resource for pages that are not wanted in their index.
I tweeted about this and two interesting questions surfaced:
Will links from noindex pages (declared in x-robots) be used for discovery?
I assume that if I did that in the headers you wouldn’t waste your time on the HTML?
— Tim Bridges (@BrowserBugs) April 20, 2020
Will links from noindex pages (declared on-page) be used for discovery?
Clarifying question: the docs say the page won’t be rendered; however, that doesn’t inherently mean the HTML wouldn’t be downloaded and parsed, right? Just that it won’t be indexed and the JS won’t be executed. So, content and links in source should still be seen & followed?
— Kyle Faber (@regal_kyle) April 20, 2020
To test this
This page is marked as noindex using x-robots and it links to another flat (non-WP) html page. This is its only link.
This page is marked as noindex on-page and it links to another flat (non-WP) html page. This is its only link.
What we are waiting to see
If one or both of the two destination pages are indexed (that are linked to separately from the above noindexed pages) then there is a good case that Google will, at least initially, use links on noindex pages for discovery.
Is this a perfect SEO test?
No, that’s now how we do things around here. Although, I did code the 4 test pages by hand like it was 1997 to make sure they weren’t automatically referenced by WordPress anywhere.