
While on a foolish errand to do some ‘experimental’ link building, I found a credit company exposing peoples’ payslips, bank statements, and more online. They didn’t seem to care much.
Important intro stuff: All personal data that was accidentally obtained was destroyed (properly), I informed the ICO and FCA after the company in question did not respond to emails or telephone calls and I made sure the security issue was resolved before posting about it, screenshots in this post are heavily redacted so all personal information is removed.
It’s also worth restating that I am not a security/infosec professional, at a stretch, I am a hobbyist. I sometimes do a little bit of research, which is either surprisingly accurate (or Google nicked it), but generally, if I discover you have some kind of security problem, it’s probably super basic and you’ve really outdone yourself.
So, let’s start with what I was trying to do.
Testing link building with automated PDF delivery
During my paternity leave last year, in August 2019, I found out that a large part of paternity leave was just kind of sitting close to a baby waiting for it to do something, which gave me a lot of time indoors that I couldn’t use productively to play games. I decided to use some of that fitful time to mess around doing some SEO experiments and generally mangling Python.
PDFs as a source for links
It is common knowledge Google can index the content of PDFs and renders them as HTML, links and all. I had previously seen a few, what looked like effective link building campaign that got various websites to host PDFs with links that were useful to their visitors, which then linked to the site that wanted to rank within the document.
Historically, I have run a few of these campaigns myself. One I recall was getting a qualified first aid instructor to write some basic first aid poster PDFs which were offered to universities all around the UK to offer on their site to download for free, which contained links back to the first aid product site. My anecdotal observation of this is that it ‘worked’. By ‘worked’, I mean a website that had been pretty much flatlining for many years, saw sustained organic growth in their search traffic and ultimately, sales.
Uploading PDFs to other websites
Taking this at face value, hand in hand with the best career advice I ever received: “if you’re doing a repetitive task on a computer, you’re using the computer wrong”, I wondered if there was a way to do this, without having to write the pesky content or bother emailing people and trying to convince them to upload the PDF.
It occurred to me, there are a lot of websites that allow you to upload files, such as PDFs, which will then be publicly accessible in a folder. In essence, a way to put my content, onto a domain, with a link, without having to go through that whole “outreach” process.
How do you go about doing this?
1. Find the footprint of sites with this functionality
It’s no secret that WordPress powers a sizeable chunk of the web and there are very easy to identify footprints, in terms of URL structures that the kind of plugins that make this functionality possible. With that known
2. Find the websites with this functionality in the right niche
This was pretty straight-forward. I used a Google CSE to search for already indexed versions of the URL footprints and got the domains back via the API. I then built a basic web crawler that I would point at those URLs, which would crawl the site and try and find where the file upload form was.
3. Write / pay for / generate content in PDF with links
Next, all you need is a PDF with say 500 words (that’s the magic number, right??) of “high quality” content about your niche, adding links as you choose
4. Upload these PDFs on the URLs you identified
Automate a browser to complete the forms, most of the forms are the same, so a few conditional statements can pass most validation (name, email, phone number, etc), flagging any failures or CAPTCHAs. I guess there could be lots of options, you could probably turk this job, too.
5. Find URL for your PDF and drop a few links to it
The filename is usually preserved and the WordPress upload files created by the plugins are also predictable, so (depending on the date) you can very quickly get the URL for your PDF, which you can drop a couple of links to get it indexed.
Something, something “domain authority”
I thought this would be a nice experiment because the PDFs themselves would not have any internal links from the sites in question, so it would be an excellent test to see if they had an impact – and if they did – shed some light on the reoccurring question about “domain authority”. Google has long claimed they don’t use “domain authority” as a signal (however you might define it), but there have been interesting cases of parasite hosting of spam on what you would call “authoritative domains” that have very quickly ranked better than they have any right to.
OH YEAH, THE HORRIFIC DATA BREACH
The trouble all started at around stage 2

I had got to the stage where I was doing some crawling of the web and I had re-used some old code to download files. This meant I was actually also downloading some PDFs as I went along, because why not? They’re on the public web, discoverable by links on a website, that should be fine, right?
This is fine
Well, it was fine, until out the corner of my eye, I noticed the script reporting downloads such as:
2019_may_statement-2019-07-27.pdf
adp-mobile-18-jul-2019-at-2215-2019-07-17.pdf
transactions-464024-11336200-11-05-2019-11-07-2019-3-2019-07-11.pdf
This didn’t sound good, so of course, I checked them out – this was peoples’ bank statements, payslips, all kinds of personal information. It had sort codes, account numbers, names, addresses, details on how much money they had (or didn’t), what they were spending money on. It was serious.
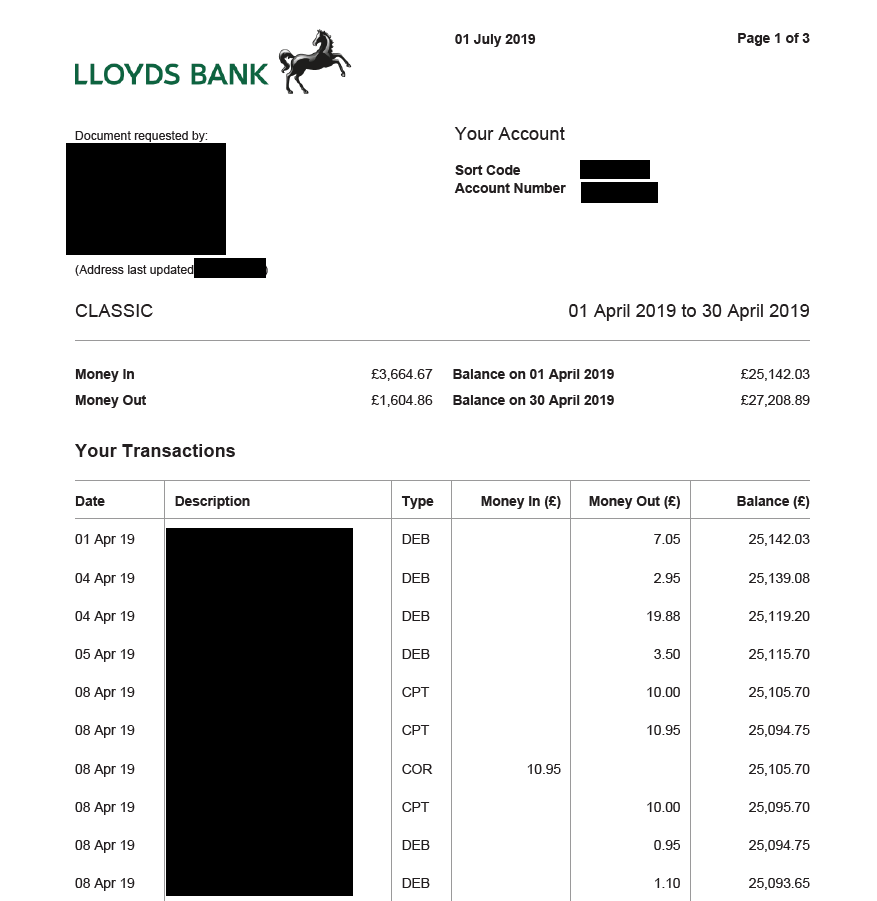

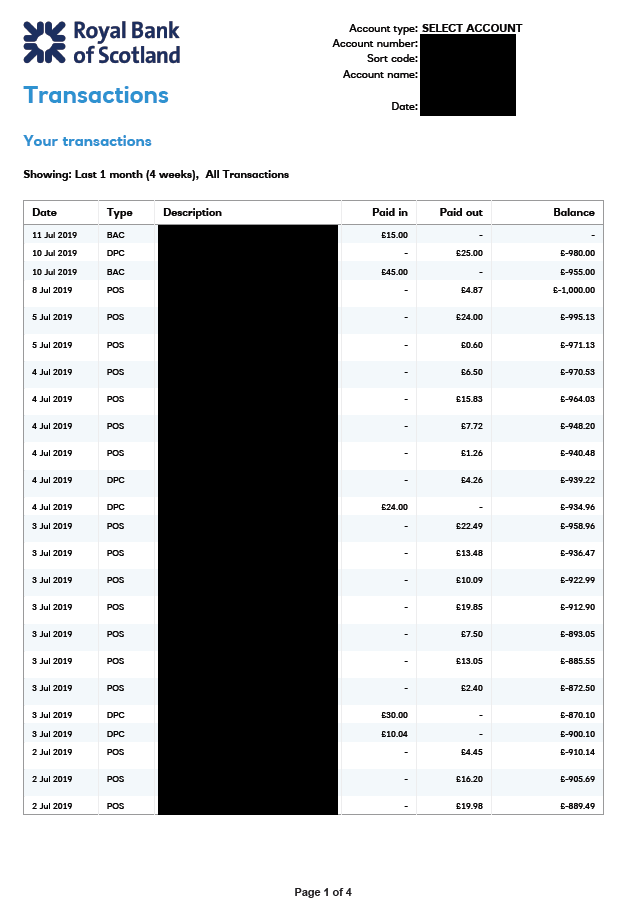
You get the idea, there were loads of these.

St Albans District Credit Union
Was the company responsible – you’d think they’d know better. I assumed they had been getting customers to upload these documents to their site as part of a credit check process. I immediately emailed them and asked urgently to contact their data protection officer or better yet (I was guessing they didn’t have one) whoever was in charge of their website security, as I didn’t want to start sending examples of this data to some random person.
Then I waited. I waited 48 hours and got absolutely no response.
So, I emailed again – both to their email addresses and their contact form, stressing how urgent and important this was.
24 hours later, I still heard nothing.
It was now the weekend, so I waited until Monday, then I tried to phone them. No answer.
On Tuesday, I tried to phone them, no response. Still no response from my emails.
At this point, I took matters into my own hands and I phoned the ICO and reported the breach, who then told me that I should inform the FCA (wow, really, this is my job now?). At this point, I was getting a little dismayed at how nobody seemed to treat any of this with any urgency (possibly also baby-induced sleep loss) and I was being asked to do the legwork to get this in front of anyone who cared.
I followed through and got on the phone to the FCA, who were much more interested. They obviously managed to get hold of St Albans, as the flaw was fixed within a few more days.
But wait, there’s more!
Once this situation had been dealt with, I went back to stage 2 – only to find another two websites within 30 minutes exposing more private data, this time exposing customer invoices and another exposing thousands of CVs publicly.
I contacted both of these sites and got some aggressive responses, including some legal threats and they wanted me to sign a document saying I wouldn’t tell anyone what I had found (which I didn’t), but both ended up dealing with the situation eventually.
I decided not to run the crawler again.
The #infosec lesson
- If you’re using common WordPress plugins for file upload, make sure they are not being stored in publicly accessible folders.
- When someone tells you about it, just fix it. Don’t ignore it, don’t threaten them.